
When our client's server failed, we were able to get them back online within just a couple of hours. For this company, however, even these short outages meant money down the drain. To remedy this, they came to us for a plan. Using High Availability and storage deduplication, we have given them 100% uptime and reduced their storage footprint by 46%.
If you're familiar with "High Availability," your first thought when you hear the term is probably "expensive." If you're not familiar with High Availability (HA), in the IT field we use it as a term for something that needs to be available even if multiple components fail. This is usually accomplished through automatic fail-over, hardware redundancies, and a lot of monitoring. Uptime (the measure of availability for a system that excludes planned maintenance) for HA systems is generally measured in 99.XXXXX% of a year, or the "Nines". For reference, five “Nines” (99.999%) of uptime is 5.26 minutes of downtime for an entire year. Can you imagine your desktop computer being unavailable for only five minutes of an entire year?
Our client came to us with a problem. Their server had experienced drive failures earlier in the year, and we were able to get them back online in a couple hours. Even this downtime had serious impacts, though. You see, this client built very large and very expensive equipment that has a multi-year wait list, the type of equipment that is shipped out on trains. Not being able to reach their data to look up drawings, vendor quotes, or part locations delayed their work and pushed back everything else in production. Over time, these delays caused enough slipping schedules to add up to a real problem in terms of money lost. The client needed as much uptime as financially reasonable, and they had a rational fear of data loss. This was where High Availability shined.
Previously, HA was only available to large companies that could throw tens of thousands of dollars at a problem. For them, loss of production far outweighed the cost of the needed infrastructure. Fortunately for our client, we had staff trained and certified to work with virtualization and storage networks, so we were able to do what large companies do on a more affordable budget.
After working with our client to determine their needs, we designed and deployed systems that utilized virtualized servers, storage, and components to provide extreme uptime and allow for maintenance of systems without taking the servers offline. We were able to do it for half the upfront cost of a traditional HA solution while minimizing the recurring license costs. Since working with the client in 2017, they have had 100% uptime for their storage server. Moreover, we were able to reduce the size of files on disk using deduplication to extend the life of their storage by several years.
Prepare yourself, here come the technical details. We're going to walk through the whole build at a medium level. We'll call this "medium level" because we'll be looking at specific configurations but glossing over parts that aren't important to this project.
At its most basic, this is a server (shown below). It has storage, memory, and compute. There are a lot of other components (like the motherboard, BIOS, network cards, power supplies, TPM, drive controllers, etc.), but for our purposes, we're ignoring those.
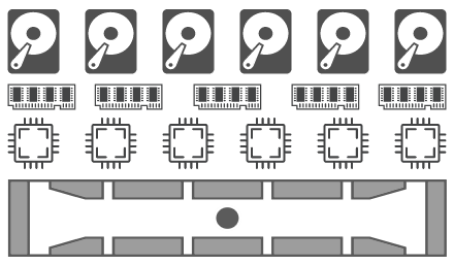
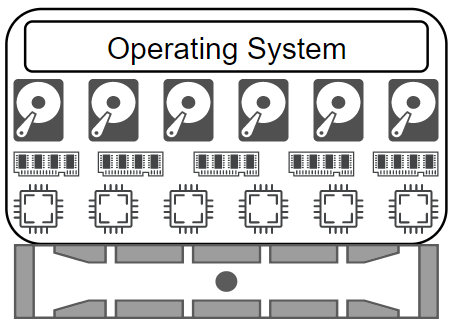
When you install an operating system on this server, all the resources are consumed by a single operating system. This means that the operating system knows it's the only thing on this hardware and that it is safe to gobble up the resources.
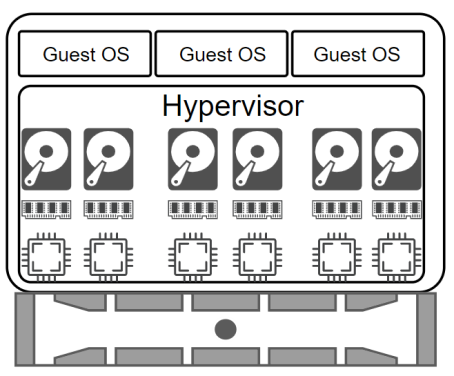
When you add virtualization with a hypervisor, however, the operating system is put inside its own little virtual world so that it shares the physical server resources. It may or may not be aware it's sharing resources, depending on the operating system and how it's configured. Most modern operating systems will be aware of the virtualization, and will configure themselves to play nice with shared resources. It's sort of like sending the operating system to kindergarten so it learns how to share.
You may be asking yourself, "What's a hypervisor? What's virtualization?" A hypervisor is software that allows abstraction of hardware. It sits between the physical hardware and the operating systems. That doesn't clear it up? It's really just an expensive emulator with a lot of features that make life better for servers and IT groups. Virtualization means the hypervisor presents the physical components of the server as virtual components to guest operating systems. In this case we're using VMware ESXi to talk to the physical components of the server and present them out as emulated virtual components. This abstraction allows you to run multiple guest servers on one physical server (sometimes called a host). It also lets you move the guest server to other physical servers, even if they have different components from different manufacturers. This gives a lot of flexibility that becomes very important when you're working with scalable workloads.
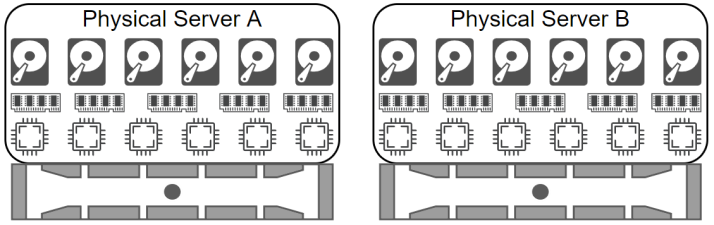
For this project, our goal is High Availability. Depending on your risk appetite, budget, and specific requirements, you can scale your resources quickly. We're deploying two physical servers in this instance. Normally you would break up the storage and compute responsibilities across different hardware, but our approach accomplishes the necessary redundancy with less hardware and less cost. Note that we're leaving out the network components for now. For HA you need to take every layer of your infrastructure into account. What happens if you have ten physical HA servers connected to a single network switch and that switch dies? This is called a "Single Point of Failure". In HA you want to avoid SPoF as much as reasonably possible.
Speaking of Single Points of Failure, the most common and most devastating component to fail is the storage. In most businesses the storage is the most utilized hardware, so it fails earlier than other components. When it fails, you could lose months or years of work if you don’t have backups or redundancy. We build our solutions with both.
We’re starting with the storage as everything will be based on this foundation. A hypervisor needs storage to live on before it can do its virtualization. We built these servers with two storage arrays. One smaller mirrored array for the hypervisor storage and a larger mirrored and spanned array for the server storage.
A mirrored array (RAID1) means that if you have eight storage drives with eight terabytes of total storage, it will be cut in half into two sets of four drives that present four terabytes of total storage to the operating system. Any data written by the operating system is written to both sets of drives for redundancy. You can lose an entire set and continue working normally while the set is repaired from its mirrored partner. A spanned array (RAID0) writes the data across the entire set of four drives rather than a single drive. These put together drastically increase redundancy and data read speeds.
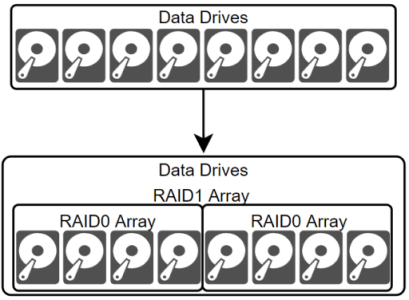
Well-designed servers have a hardware-based RAID controller. This is a piece of hardware (that should have redundancy) that controls how the individual storage drives interface with the system. Drives combined by the RAID controller are presented to the operating system as a logical drive. The operating system sees them as one single drive rather than eight drives split into two sets, which makes life easier for everyone. Now we’ve got our storage prepared for the hypervisor so let's put that into play.
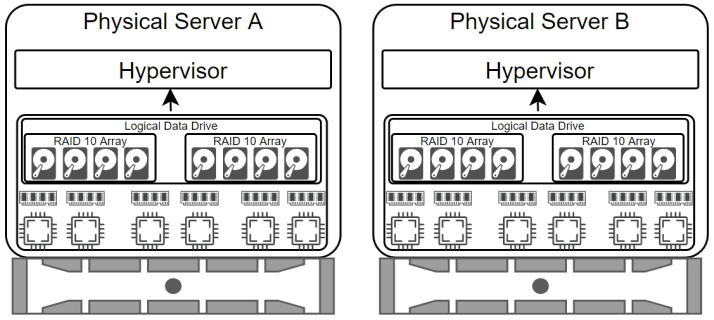
With the hypervisor installed on the servers we could go ahead and install guest servers, but we're not Highly Available yet. We've got two servers that can share their own resources, but they can't failover to the other server, and there's no replication. To accomplish these goals we're going to virtualize further. You'll notice in the graphic below that we now have two hypervisors. A physical hypervisor and a storage hypervisor. We're adding another layer of abstraction between the physical server resources and the guest operating systems. This gets a bit complicated. The physical drives are part of RAID10 arrays that present to the physical hypervisor as a single logical drive. The physical hypervisor then presents this logical drive as a virtual logical drive to the storage hypervisor which converts it to a virtual logical drive and presents it back to the hypervisor so it can present it to the guest operating systems.
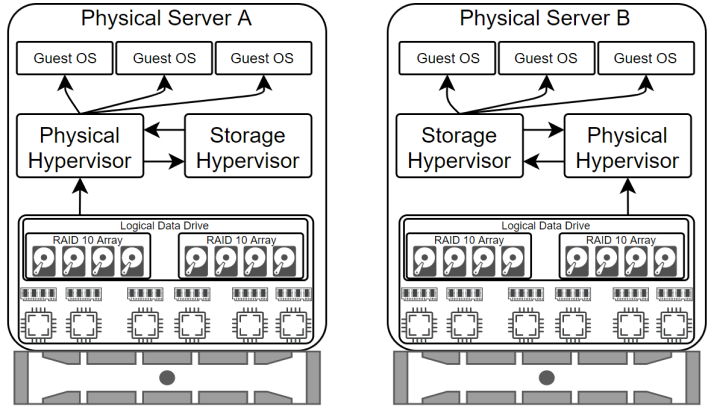
Pretty crazy right? Why would we present storage from the physical hypervisor back to itself? We're doing this to allow us to replicate the data between the physical servers and allow the physical hypervisors to connect to each other’s storage. The physical hypervisors don't know how to do this on their own so they rely on the storage hypervisor to handle it for them. Here are some scenarios where this redundant connection is important:
- If the storage controller of one server fails, that server is already connected to the other server and will continue working through the other server’s storage.
- If an entire physical server goes offline, all the guest operating system data is already replicated on the other physical server. The guest operating system is immediately migrated to the other physical server with no downtime.
- If we need to add memory to a physical server, reboot it, or perform upgrades, the guest operating systems can be migrated, while online, to the other physical server.
When it's all done, we have a mess of network cables and a lot of redundant connections, which is what we want for High Availability. The physical hypervisor is connected to its own local storage hypervisor as well as the remote storage hypervisor. This is called "Multipathing". It means the hypervisor recognizes that the storage for the guest operating systems is redundant so it can connect to both storage locations for the files needed to run the guest operating systems. The storage hypervisors are connected to each other which allows them to replicate data between the physical servers. This means we always have a live copy of the guest operating system data. Remember the network connections mentioned earlier? Here's what it looks like with all the redundant network connections:
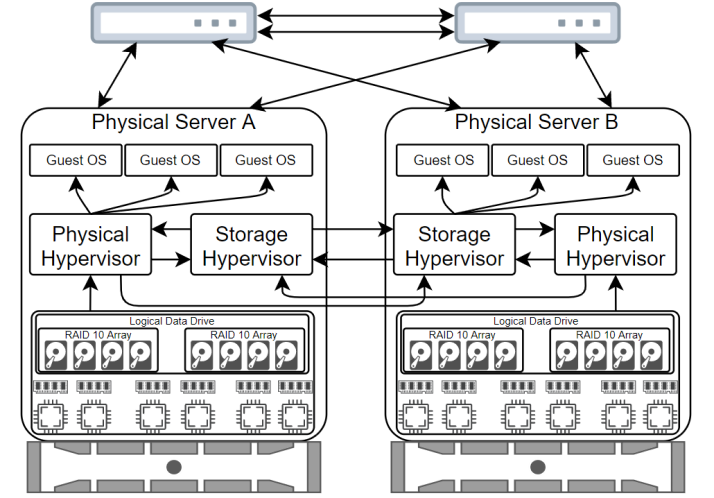
Please remember, redundancy is not the same as backup. Redundancy means components can fail and service won't be lost, but if the entire building catches on fire, you're still losing data. Backups are always important. For this client, the backups run nightly to another server across town, the backups are then written to tapes to be stored off-site and off-line. If the physical servers at their office are destroyed, they will still have the backups from the previous night, and these can be brought on-line on the backup server in about an hour.
The cherry on top of this High Availability cake is the data deduplication. Data deduplication is generally a function of the guest operating system. It can be done at other layers, but Windows Server supports it natively, so we let it handle this function. Storage is often the most expensive component for a server, so you want to get the most use out of it you can. Deduplication looks for blocks of data that are the same across multiple files and stores it only once. Look back over this web page and see how many times "hypervisor" appears. With deduplication, the data for the word "hypervisor" is stored on the disk only once. When we moved our client's data from their old server to the new High Availability servers, the data deduplication reduced their data footprint on disk by 46%. This allows for several additional years before they'll need to upgrade their storage.